








Hive Data types and Merging tables , table to table copy










[training@localhost ~]$ cat > tmpr.txt
xxxxx1950xxx23xx
xxxxx1950xxx25xx
xxxxx1950xxx24xx
xxxxx1951xxx21xx
xxxxx1951xxx20xx
[training@localhost ~]$
hive> create table raw(line string);
OK
Time taken: 0.077 seconds
hive> load data local inpath 'tmpr.txt' into table raw;
Copying data from file:/home/training/tmpr.txt
Copying file: file:/home/training/tmpr.txt
Loading data to table practice.raw
OK
Time taken: 0.279 seconds
hive> create table tmpr(y int, t int);
OK
Time taken: 0.051 seconds
hive> insert overwrite table tmpr
> select substr(line,6,4), substr(line,13,2) from raw;
hive> select * from tmpr
> ;
OK
1950 23
1950 25
1950 24
1951 21
1951 20
Time taken: 0.101 seconds
hive> create table result(y int, max int, min int);
OK
Time taken: 0.05 seconds
hive> insert overwrite table result
> select y, max(t), min(t) from tmpr group by y;
hive> select * from result;
OK
1950 25 23
1951 21 20
Time taken: 0.161 seconds
hive>
___________________________
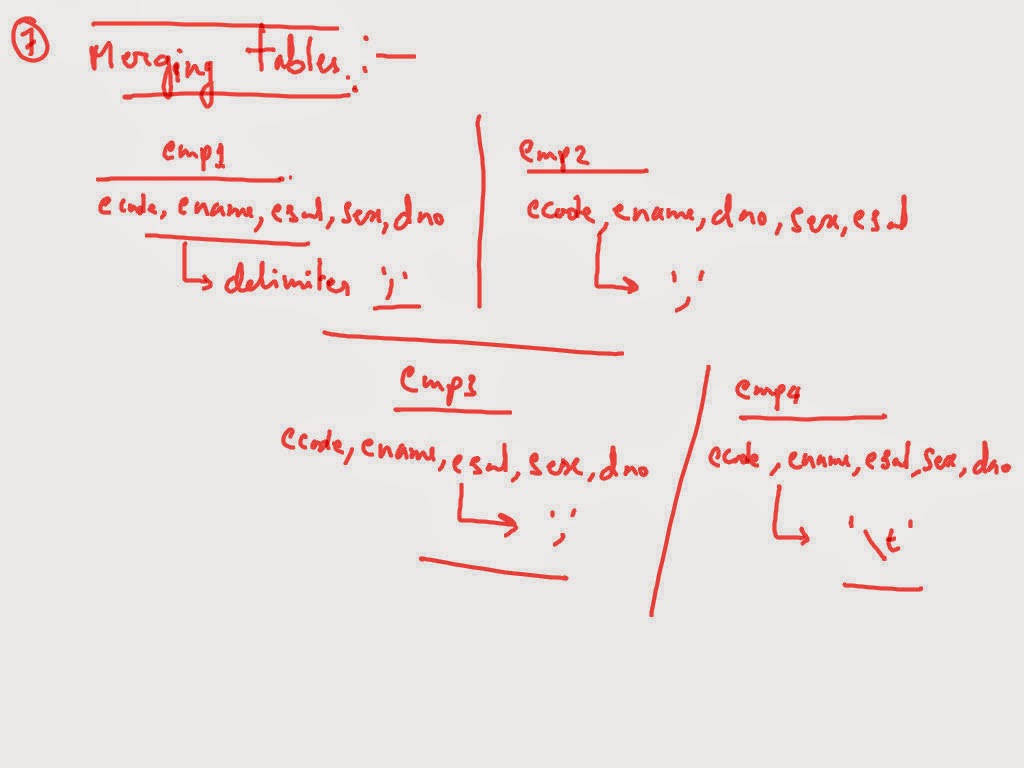
Merging
____________________________
[training@localhost ~]$ cat > sales1
p1,2000
p2,3000
p1,1000
[training@localhost ~]$ cat > sales2
3000,p1
4000,p1
60000,p2
[training@localhost ~]$ cat > sales3
p1,6000
p2,7000
[training@localhost ~]$ cat > sales4
p1 40000
p2 2000
hive> create table s1(pid string, amt int)
> row format delimited fields terminated by ',';
OK
Time taken: 0.073 seconds
hive> create table s2(amt int, pid string)
> row format delimited fields terminated by ',';
OK
Time taken: 0.044 seconds
hive> create table s3(pid string, amt int)
> row format delimited fields terminated by '\t';
OK
Time taken: 0.044 seconds
hive> load data local inpath 'sales1' into table s1;
Copying data from file:/home/training/sales1
Copying file: file:/home/training/sales1
Loading data to table practice.s1
OK
Time taken: 0.119 seconds
hive> load data local inpath 'sales3' into table s1;
Copying data from file:/home/training/sales3
Copying file: file:/home/training/sales3
Loading data to table practice.s1
OK
Time taken: 0.161 seconds
hive> load data local inpath 'sales2' into table s2;
Copying data from file:/home/training/sales2
Copying file: file:/home/training/sales2
Loading data to table practice.s2
OK
Time taken: 0.161 seconds
hive> load data local inpath 'sales4' into table s3;
Copying data from file:/home/training/sales4
Copying file: file:/home/training/sales4
Loading data to table practice.s3
OK
Time taken: 0.143 seconds
hive> create table sales like s1;
OK
Time taken: 0.061 seconds
hive> insert overwrite table sales
> select * from (
> select pid, amt from s1
> union all
> select pid, amt from s2
> union all
> select pid, amt from s3 ) s ;
hive> select * from sales;
OK
p1 2000
p2 3000
p1 1000
p1 6000
p2 7000
p1 3000
p1 4000
p2 60000
p1 40000
p2 2000
Time taken: 0.11 seconds
hive>
[training@localhost ~]$ hadoop fs -ls /user/hive/warehouse/practice.db/sales
Found 1 items
-rw-r--r-- 1 training supergroup 82 2015-04-19 02:41 /user/hive/warehouse/practice.db/sales/000000_0
[training@localhost ~]$ hadoop fs -cat /user/hive/warehouse/practice.db/sales/000000_0
p1,2000
p2,3000
p1,1000
p1,6000
p2,7000
p1,3000
p1,4000
p2,60000
p1,40000
p2,2000
[training@localhost ~]$
Hive : Loading data into hive tables







[training@localhost ~]$ cat > samp1
100,200,300
200,500,500
12,345,567
hive> use practice;
OK
Time taken: 0.037 seconds
hive> show tables;
OK
ramp2
sample1
sample2
sample3
Time taken: 0.079 seconds
hive> create table samp1(a int, b int , c int);
OK
Time taken: 0.058 seconds
hive> load data local inpath 'samp1' into table samp1;
Copying data from file:/home/training/samp1
Copying file: file:/home/training/samp1
Loading data to table practice.samp1
OK
Time taken: 0.117 seconds
hive> select * from samp1;
OK
NULL NULL NULL
NULL NULL NULL
NULL NULL NULL
Time taken: 0.126 seconds
hive>
hive> create table samp2(a int, b int, c int)
> row format delimited fields terminated by ',';
OK
Time taken: 0.048 seconds
hive> load data local inpath 'samp1' into table samp2;
Copying data from file:/home/training/samp1
Copying file: file:/home/training/samp1
Loading data to table practice.samp2
OK
Time taken: 0.152 seconds
hive> select * from samp2;
OK
100 200 300
200 500 500
12 345 567
Time taken: 0.083 seconds
hive> describe samp2;
OK
a int
b int
c int
Time taken: 0.062 seconds
hive>
[training@localhost ~]$ cat emp
101,vino,26000,m,11
102,Sri,25000,f,11
103,mohan,13000,m,13
104,lokitha,8000,f,12
105,naga,6000,m,13
101,janaki,10000,f,12
107,kkk,30000,m,15
108,kkdk,40000,f,20
________________________
loading from hdfs to table:
[training@localhost ~]$ hadoop fs -copyFromLocal emp weekend
[training@localhost ~]$ hadoop fs -cat weekend/emp
101,vino,26000,m,11
102,Sri,25000,f,11
103,mohan,13000,m,13
104,lokitha,8000,f,12
105,naga,6000,m,13
101,janaki,10000,f,12
107,kkk,30000,m,15
108,kkdk,40000,f,20
hive> create table new like emp;
OK
Time taken: 0.075 seconds
hive> load data inpath 'weekend/emp' into table new;
Loading data to table practice.new
OK
Time taken: 0.145 seconds
hive> select * from new;
OK
101 vino 26000 m 11
102 Sri 25000 f 11
103 mohan 13000 m 13
104 lokitha 8000 f 12
105 naga 6000 m 13
101 janaki 10000 f 12
107 kkk 30000 m 15
108 kkdk 40000 f 20
Time taken: 0.103 seconds
hive>
custom locations for inner and external tables



hive> use practice;
OK
Time taken: 0.037 seconds
hive> create table sample1(line string)
> location '/user/mypath';
OK
Time taken: 0.081 seconds
hive> load data local inpath 'file1' into table sample1;
Copying data from file:/home/training/file1
Copying file: file:/home/training/file1
Loading data to table practice.sample1
OK
Time taken: 0.138 seconds
hive> create external table sample2(line string)
> location '/user/urpath';
OK
Time taken: 0.05 seconds
hive> load data local inpath 'file2' into table sample2;
Copying data from file:/home/training/file2
Copying file: file:/home/training/file2
Loading data to table practice.sample2
OK
Time taken: 0.192 seconds
hive> select * from sample2;
OK
bbbbbbbbbb
bbbbbbbbbb
Time taken: 0.111 seconds
hive>
[training@localhost ~]$ hadoop fs -ls /user/mypath
Found 1 items
-rw-r--r-- 1 training supergroup 16 2015-04-19 00:20 /user/mypath/file1
[training@localhost ~]$ hadoop fs -ls /user/urpath
Found 1 items
-rw-r--r-- 1 training supergroup 22 2015-04-19 00:22 /user/urpath/file2
_________________________________-
[training@localhost ~]$ hadoop fs -mkdir /user/d1/p1
[training@localhost ~]$ hadoop fs -copyFromLocal file3 /user/d1/p1
[training@localhost ~]$
hive> create table sample3(line string)
> location '/user/d1/p1';
OK
Time taken: 0.059 seconds
hive> select * from sample3;
OK
cvxccccccccccc
cccccccccccccc
cccccccccccccc
Time taken: 0.11 seconds
hive>
__________________________________________________
hive> create table ramp1(line string)
> location '/user/myramp';
OK
Time taken: 0.04 seconds
hive> create external table ramp2(line string)
> location '/user/myramp';
OK
Time taken: 0.043 seconds
hive> load data local inpath 'file1' into table ramp1;
Copying data from file:/home/training/file1
Copying file: file:/home/training/file1
Loading data to table practice.ramp1
OK
Time taken: 0.173 seconds
hive> select * from ramp2;
OK
aaaaa
aaaaaaaaa
Time taken: 0.074 seconds
hive> load data local inpath 'file2' into table ramp2;
Copying data from file:/home/training/file2
Copying file: file:/home/training/file2
Loading data to table practice.ramp2
OK
Time taken: 0.147 seconds
hive> select * from ramp1;
OK
aaaaa
aaaaaaaaa
bbbbbbbbbb
bbbbbbbbbb
Time taken: 0.112 seconds
hive> drop table ramp1;
OK
Time taken: 0.11 seconds
hive> select * from ramp2;
OK
Time taken: 0.051 seconds
hive>
__________________
Example9:(number of employees in the organization)
Example9: Emp9.java
___________________________________________________________________________________________________
[training@localhost ~]$ hadoop fs -cat mr/emp
101,ravi,10000,hyd,m,11
102,rani,12000,pune,f,12
103,ravina,13000,hyd,f,13
104,rana,14000,hyd,m,11
105,roopa,15000,pune,f,12
106,razeena,16000,pune,f,12
107,susma,14000,hyd,f,12
108,sampurnesh,20000,delhi,m,13
109,samantha,18000,pune,f,12
110,kamal,19000,delhi,m,11
111,krupa,21000,delhi,m,11
112,kapoor,16000,pune,m,12
schema : ecode, name, sal, city, sex, dno
Task: number of employees in the organization
Sql : select count(*) from emp;
_________
Emp9.java
_________
package bharath.sreeram.big.halitcs;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class Emp9
{
public static class MyMap extends Mapper<LongWritable,Text,Text,IntWritable>
{
public void map(LongWritable k,Text v, Context con)
throws IOException, InterruptedException
{
con.write(new Text("BigHalitics"), new IntWritable(1));
}
}
public static class MyRed extends Reducer<Text,IntWritable,IntWritable,Text>
{
public void reduce(Text k, Iterable<IntWritable> vlist, Context con)
throws IOException , InterruptedException
{
int tot=0;
for(IntWritable v:vlist)
{
tot+=v.get();
}
con.write(new IntWritable(tot), new Text());
}
}
public static void main(String[] args) throws Exception
{
Configuration c = new Configuration();
Job j= new Job(c,"Test");
j.setJarByClass(Emp9.class);
j.setMapperClass(MyMap.class);
j.setReducerClass(MyRed.class);
j.setOutputKeyClass(Text.class);
j.setOutputValueClass(IntWritable.class);
Path p1 = new Path(args[0]);
Path p2 = new Path(args[1]);
FileInputFormat.addInputPath(j,p1);
FileOutputFormat.setOutputPath(j,p2);
System.exit(j.waitForCompletion(true) ? 0:1);
}
}
Submitting Hadoop Job:
$ hadoop jar Desktop/mr.jar bharath.sreeram.big.halitcs.Emp9 mr/emp Result9
Output of the Job:
$ hadoop fs -cat Result9/part-r-00000
12
Learn more »
___________________________________________________________________________________________________
[training@localhost ~]$ hadoop fs -cat mr/emp
101,ravi,10000,hyd,m,11
102,rani,12000,pune,f,12
103,ravina,13000,hyd,f,13
104,rana,14000,hyd,m,11
105,roopa,15000,pune,f,12
106,razeena,16000,pune,f,12
107,susma,14000,hyd,f,12
108,sampurnesh,20000,delhi,m,13
109,samantha,18000,pune,f,12
110,kamal,19000,delhi,m,11
111,krupa,21000,delhi,m,11
112,kapoor,16000,pune,m,12
schema : ecode, name, sal, city, sex, dno
Task: number of employees in the organization
Sql : select count(*) from emp;
_________
Emp9.java
_________
package bharath.sreeram.big.halitcs;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class Emp9
{
public static class MyMap extends Mapper<LongWritable,Text,Text,IntWritable>
{
public void map(LongWritable k,Text v, Context con)
throws IOException, InterruptedException
{
con.write(new Text("BigHalitics"), new IntWritable(1));
}
}
public static class MyRed extends Reducer<Text,IntWritable,IntWritable,Text>
{
public void reduce(Text k, Iterable<IntWritable> vlist, Context con)
throws IOException , InterruptedException
{
int tot=0;
for(IntWritable v:vlist)
{
tot+=v.get();
}
con.write(new IntWritable(tot), new Text());
}
}
public static void main(String[] args) throws Exception
{
Configuration c = new Configuration();
Job j= new Job(c,"Test");
j.setJarByClass(Emp9.class);
j.setMapperClass(MyMap.class);
j.setReducerClass(MyRed.class);
j.setOutputKeyClass(Text.class);
j.setOutputValueClass(IntWritable.class);
Path p1 = new Path(args[0]);
Path p2 = new Path(args[1]);
FileInputFormat.addInputPath(j,p1);
FileOutputFormat.setOutputPath(j,p2);
System.exit(j.waitForCompletion(true) ? 0:1);
}
}
Submitting Hadoop Job:
$ hadoop jar Desktop/mr.jar bharath.sreeram.big.halitcs.Emp9 mr/emp Result9
Output of the Job:
$ hadoop fs -cat Result9/part-r-00000
12
Example8:(Minimum salary of the organization)
Example 8: Emp8.java
_____________________________________________________________________________________
[training@localhost ~]$ hadoop fs -cat mr/emp
101,ravi,10000,hyd,m,11
102,rani,12000,pune,f,12
103,ravina,13000,hyd,f,13
104,rana,14000,hyd,m,11
105,roopa,15000,pune,f,12
106,razeena,16000,pune,f,12
107,susma,14000,hyd,f,12
108,sampurnesh,20000,delhi,m,13
109,samantha,18000,pune,f,12
110,kamal,19000,delhi,m,11
111,krupa,21000,delhi,m,11
112,kapoor,16000,pune,m,12
schema : ecode, name, sal, city, sex, dno
Task: Minimum salary of the organization
Sql : select min(sal) from emp;
_________
Emp8.java
_________
package bharath.sreeram.big.halitcs;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class Emp8
{
public static class MyMap extends Mapper<LongWritable,Text,Text,IntWritable>
{
public void map(LongWritable k,Text v, Context con)
throws IOException, InterruptedException
{
String line = v.toString();
String[] w=line.split(",");
int sal=Integer.parseInt(w[2]);
con.write(new Text("BigHalitics"), new IntWritable(sal));
}
}
public static class MyRed extends Reducer<Text,IntWritable,IntWritable,Text>
{
public void reduce(Text k, Iterable<IntWritable> vlist, Context con)
throws IOException , InterruptedException
{
int min=0;
int cnt=0;
for(IntWritable v:vlist)
{
int sal=v.get();
cnt++;
if(cnt==1) min=sal;
min=Math.min(min, sal);
}
con.write(new IntWritable(min), new Text());
}
}
public static void main(String[] args) throws Exception
{
Configuration c = new Configuration();
Job j= new Job(c,"Test");
j.setJarByClass(Emp8.class);
j.setMapperClass(MyMap.class);
j.setReducerClass(MyRed.class);
j.setOutputKeyClass(Text.class);
j.setOutputValueClass(IntWritable.class);
Path p1 = new Path(args[0]);
Path p2 = new Path(args[1]);
FileInputFormat.addInputPath(j,p1);
FileOutputFormat.setOutputPath(j,p2);
System.exit(j.waitForCompletion(true) ? 0:1);
}
}
Submitting Job:
$ hadoop jar Desktop/mr.jar bharath.sreeram.big.halitcs.Emp8 mr/emp Result8
Output of the Job:
$ hadoop fs -cat Result8/part-r-00000
10000
Learn more »
_____________________________________________________________________________________
[training@localhost ~]$ hadoop fs -cat mr/emp
101,ravi,10000,hyd,m,11
102,rani,12000,pune,f,12
103,ravina,13000,hyd,f,13
104,rana,14000,hyd,m,11
105,roopa,15000,pune,f,12
106,razeena,16000,pune,f,12
107,susma,14000,hyd,f,12
108,sampurnesh,20000,delhi,m,13
109,samantha,18000,pune,f,12
110,kamal,19000,delhi,m,11
111,krupa,21000,delhi,m,11
112,kapoor,16000,pune,m,12
schema : ecode, name, sal, city, sex, dno
Task: Minimum salary of the organization
Sql : select min(sal) from emp;
_________
Emp8.java
_________
package bharath.sreeram.big.halitcs;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class Emp8
{
public static class MyMap extends Mapper<LongWritable,Text,Text,IntWritable>
{
public void map(LongWritable k,Text v, Context con)
throws IOException, InterruptedException
{
String line = v.toString();
String[] w=line.split(",");
int sal=Integer.parseInt(w[2]);
con.write(new Text("BigHalitics"), new IntWritable(sal));
}
}
public static class MyRed extends Reducer<Text,IntWritable,IntWritable,Text>
{
public void reduce(Text k, Iterable<IntWritable> vlist, Context con)
throws IOException , InterruptedException
{
int min=0;
int cnt=0;
for(IntWritable v:vlist)
{
int sal=v.get();
cnt++;
if(cnt==1) min=sal;
min=Math.min(min, sal);
}
con.write(new IntWritable(min), new Text());
}
}
public static void main(String[] args) throws Exception
{
Configuration c = new Configuration();
Job j= new Job(c,"Test");
j.setJarByClass(Emp8.class);
j.setMapperClass(MyMap.class);
j.setReducerClass(MyRed.class);
j.setOutputKeyClass(Text.class);
j.setOutputValueClass(IntWritable.class);
Path p1 = new Path(args[0]);
Path p2 = new Path(args[1]);
FileInputFormat.addInputPath(j,p1);
FileOutputFormat.setOutputPath(j,p2);
System.exit(j.waitForCompletion(true) ? 0:1);
}
}
Submitting Job:
$ hadoop jar Desktop/mr.jar bharath.sreeram.big.halitcs.Emp8 mr/emp Result8
Output of the Job:
$ hadoop fs -cat Result8/part-r-00000
10000
Example7:(Maximum salary of the organization)
Example 7: Emp7.java
_______________________________________________________________________________________________
[training@localhost ~]$ hadoop fs -cat mr/emp
101,ravi,10000,hyd,m,11
102,rani,12000,pune,f,12
103,ravina,13000,hyd,f,13
104,rana,14000,hyd,m,11
105,roopa,15000,pune,f,12
106,razeena,16000,pune,f,12
107,susma,14000,hyd,f,12
108,sampurnesh,20000,delhi,m,13
109,samantha,18000,pune,f,12
110,kamal,19000,delhi,m,11
111,krupa,21000,delhi,m,11
112,kapoor,16000,pune,m,12
schema : ecode, name, sal, city, sex, dno
Task: Maximum salary of the organization
Sql : select max(sal) from emp;
________
Emp7.java
________
package bharath.sreeram.big.halitcs;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class Emp7
{
public static class MyMap extends Mapper<LongWritable,Text,Text,IntWritable>
{
public void map(LongWritable k,Text v, Context con)
throws IOException, InterruptedException
{
String line = v.toString();
String[] w=line.split(",");
int sal=Integer.parseInt(w[2]);
con.write(new Text("BigHalitics"), new IntWritable(sal));
}
}
public static class MyRed extends Reducer<Text,IntWritable,IntWritable,Text>
{
public void reduce(Text k, Iterable<IntWritable> vlist, Context con)
throws IOException , InterruptedException
{
int max=0;
for(IntWritable v:vlist)
{
max=Math.max(max, v.get());
}
con.write(new IntWritable(max), new Text());
}
}
public static void main(String[] args) throws Exception
{
Configuration c = new Configuration();
Job j= new Job(c,"Test");
j.setJarByClass(Emp7.class);
j.setMapperClass(MyMap.class);
j.setReducerClass(MyRed.class);
j.setOutputKeyClass(Text.class);
j.setOutputValueClass(IntWritable.class);
Path p1 = new Path(args[0]);
Path p2 = new Path(args[1]);
FileInputFormat.addInputPath(j,p1);
FileOutputFormat.setOutputPath(j,p2);
System.exit(j.waitForCompletion(true) ? 0:1);
}
}
Submitting Hadoop Job:
$ hadoop jar Desktop/mr.jar bharath.sreeram.big.halitcs.Emp7 mr/emp Result7
Output of the Job:
$ hadoop fs -cat Result7/part-r-00000
21000
Learn more »
_______________________________________________________________________________________________
[training@localhost ~]$ hadoop fs -cat mr/emp
101,ravi,10000,hyd,m,11
102,rani,12000,pune,f,12
103,ravina,13000,hyd,f,13
104,rana,14000,hyd,m,11
105,roopa,15000,pune,f,12
106,razeena,16000,pune,f,12
107,susma,14000,hyd,f,12
108,sampurnesh,20000,delhi,m,13
109,samantha,18000,pune,f,12
110,kamal,19000,delhi,m,11
111,krupa,21000,delhi,m,11
112,kapoor,16000,pune,m,12
schema : ecode, name, sal, city, sex, dno
Task: Maximum salary of the organization
Sql : select max(sal) from emp;
________
Emp7.java
________
package bharath.sreeram.big.halitcs;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class Emp7
{
public static class MyMap extends Mapper<LongWritable,Text,Text,IntWritable>
{
public void map(LongWritable k,Text v, Context con)
throws IOException, InterruptedException
{
String line = v.toString();
String[] w=line.split(",");
int sal=Integer.parseInt(w[2]);
con.write(new Text("BigHalitics"), new IntWritable(sal));
}
}
public static class MyRed extends Reducer<Text,IntWritable,IntWritable,Text>
{
public void reduce(Text k, Iterable<IntWritable> vlist, Context con)
throws IOException , InterruptedException
{
int max=0;
for(IntWritable v:vlist)
{
max=Math.max(max, v.get());
}
con.write(new IntWritable(max), new Text());
}
}
public static void main(String[] args) throws Exception
{
Configuration c = new Configuration();
Job j= new Job(c,"Test");
j.setJarByClass(Emp7.class);
j.setMapperClass(MyMap.class);
j.setReducerClass(MyRed.class);
j.setOutputKeyClass(Text.class);
j.setOutputValueClass(IntWritable.class);
Path p1 = new Path(args[0]);
Path p2 = new Path(args[1]);
FileInputFormat.addInputPath(j,p1);
FileOutputFormat.setOutputPath(j,p2);
System.exit(j.waitForCompletion(true) ? 0:1);
}
}
Submitting Hadoop Job:
$ hadoop jar Desktop/mr.jar bharath.sreeram.big.halitcs.Emp7 mr/emp Result7
Output of the Job:
$ hadoop fs -cat Result7/part-r-00000
21000
Subscribe to:
Comments (Atom)


.jpg)


